Storage and Infrastructure¶
In previous tutorials, we've run flow and tasks entirely in a local execution environment using the local file system to store flow scripts.
For production workflows, you'll most likely want to configure deployments that create flow runs in remote execution environments — a VM, a Docker container, or a Kubernetes cluster, for example. These deployments require remote storage and infrastructure blocks that specify where your flow code is stored and how the flow run execution environment should be configured.
Let's unpack these terms.
In Prefect, blocks are a primitive that enable you to specify configuration for interacting with external systems.
Storage blocks contain configuration for interacting with file storage such as a remote filesystem, AWS S3, and so on.
Infrastructure blocks contain settings that agents use to stand up execution infrastructure for a flow run.
Prerequisites¶
The steps demonstrated in this tutorial assume you have access to a storage location in a third-party service such as AWS, Azure, or GitHub.
To create a storage block, you will need the storage location (for example, a bucket or container name) and valid authentication details such as access keys or connection strings.
To use a remote storage block when creating deployments or using storage blocks within your flow script, you must install the required library for the storage service.
| Service | Library |
|---|---|
| AWS S3 | s3fs |
| Azure | adlfs |
| GCS | gcsfs |
| GitHub | git CLI |
For example:
$ pip install s3fs
Storage¶
As mentioned previously, storage blocks contain configuration for interacting with file storage. This includes:
- Remote storage on a filesystem supported by
fsspec - AWS S3
- Azure Blob Storage
- Google Cloud Storage
- SMB shares
- GitHub repositories
- Docker image
Storage blocks enable Prefect to save and reference deployment artifacts (such as your flow scripts) to a location where they can be retrieved for future flow run execution.
Your flow code may also load storage blocks to access configuration for accessing storage, such as for reading or saving files.
Create a storage block¶
Most users will find it easiest to configure new storage blocks through the Prefect server or Prefect Cloud UI.
You can see any previously configured storage blocks by opening the Prefect UI and navigating to the Blocks page.
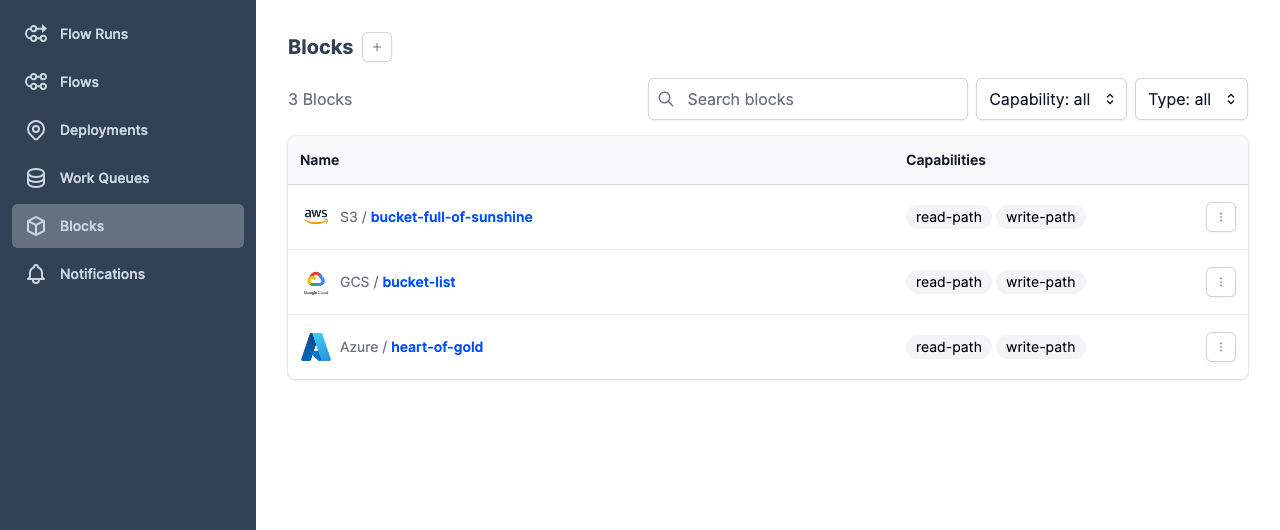
To create a new block, select the + button on this page, or if you haven't previously created any blocks, New Block. Prefect displays a page of available block types.
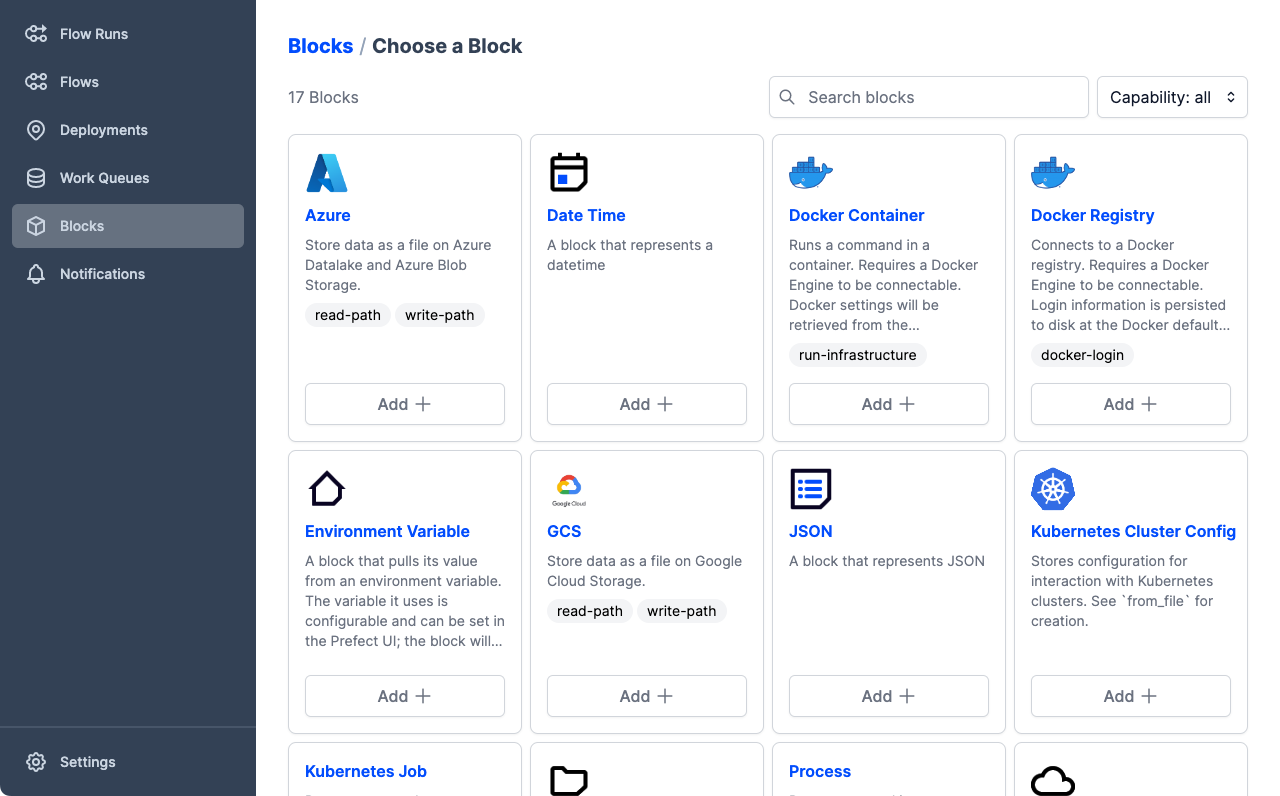
For this tutorial example, we'll use the AWS S3 block as an example. If you use a different cloud storage service or solution, feel free to use the appropriate block type. The process is similar for all blocks, though the configuration options are slightly different, reflecting the authentication requirements of different cloud services.
Scroll down the list of blocks and find the S3 block, then select Add + to configure a new storage block based on this block type. Prefect displays a Create page that enables specifying storage settings.
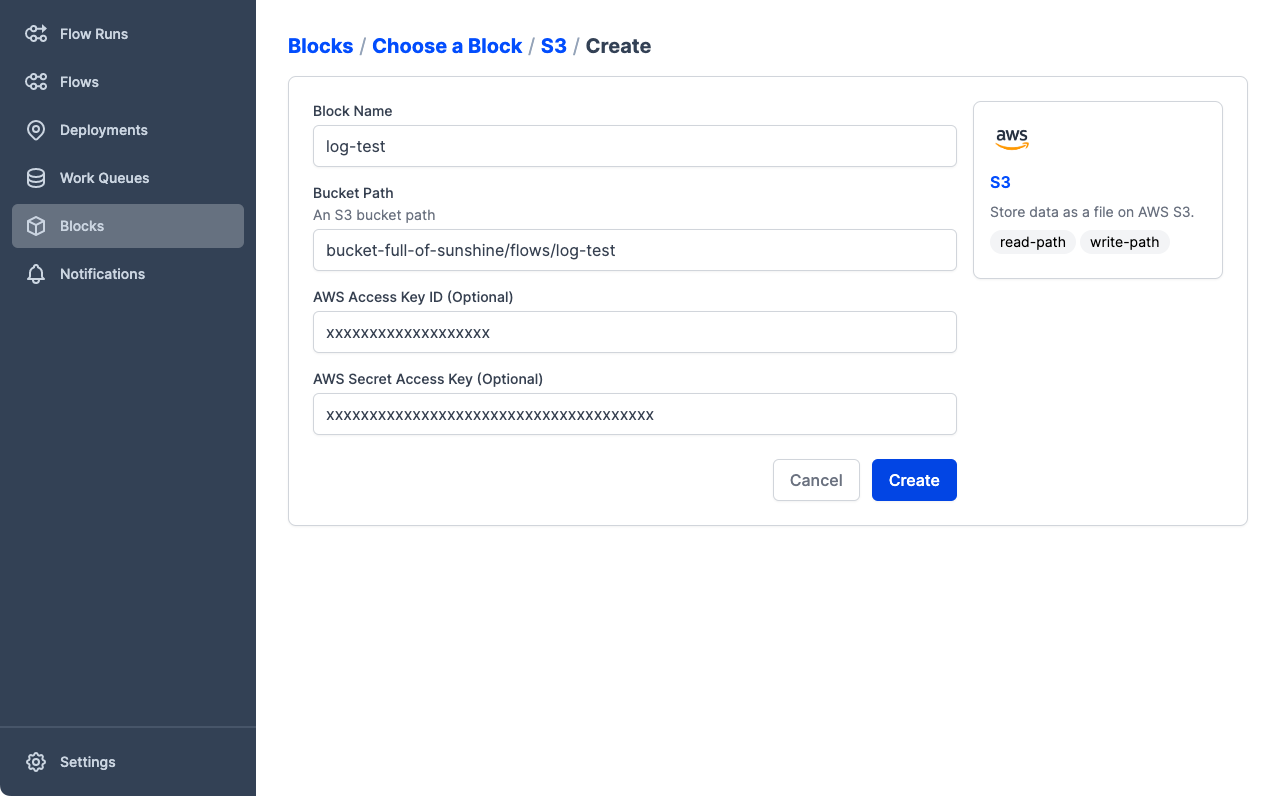
Enter the configuration for your storage.
- Block Name is the name by which your block is referenced. The name must only contain lowercase letters, numbers, and dashes.
- Bucket Path is the name of the bucket or container and, optionally, path to a folder within the bucket. If the folder does not exist it will be created. For example:
my-bucket/my/path. - AWS Access Key ID and AWS Secret Access Key take the respective authentication keys if they are needed to access the storage location.
In this example we've specified a storage location that could be used by the flow example from the deployments tutorial.
- The name
log-testmakes it clear what flow code is stored in this location. bucket-full-of-sunshine/flows/log-testspecifies the bucket namebucket-full-of-sunshineand the path to use within that bucket:/flows/log-test.- This bucket requires an authenticated role, so we include the Access Key ID and Secret Access Key values.
Secrets are obfuscated
Note that, once you save a block definition that contains sensitive data such as access keys, connection strings, or passwords, this data is obfuscated when viewed in the UI. You may update sensitive data, replacing it in the Prefect database, but you cannot view or copy this data from the UI.
This data is also obfuscated when persisted to deployment YAML files.
Select Create to create the new storage block. Prefect displays the details of the new block, including a code example for using the block within your flow code.
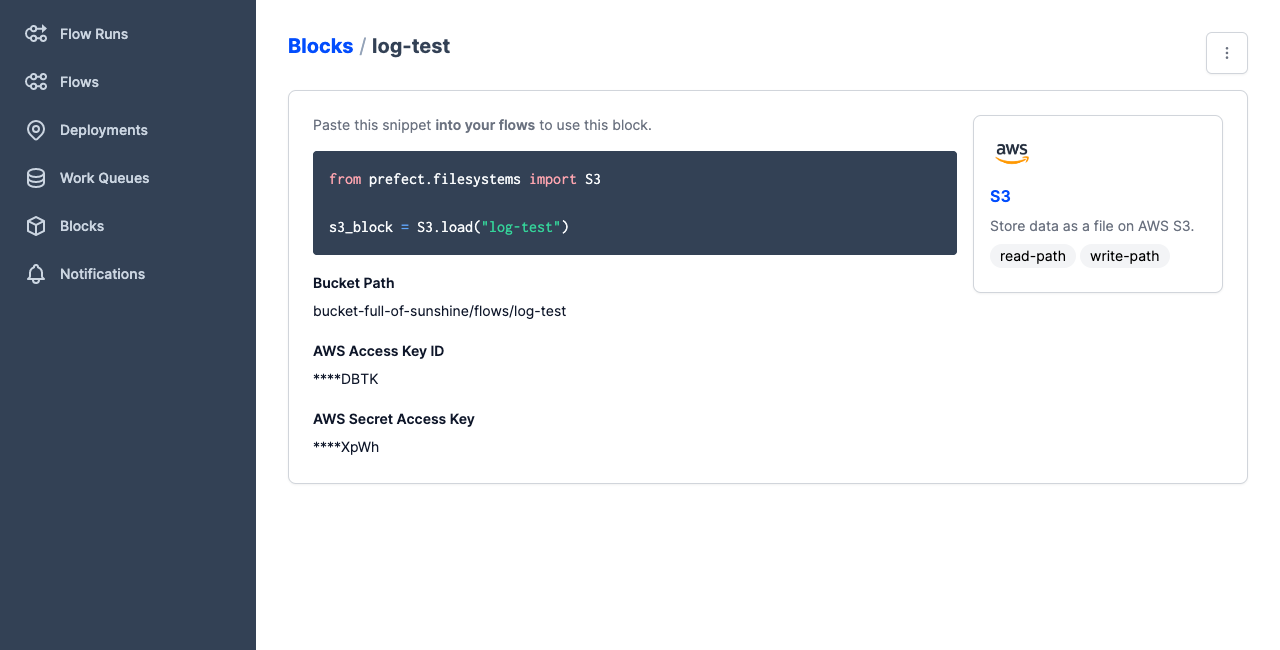
Blocks and deployments are specific to a server or Prefect Cloud workspace
Note that, if you ran through this tutorial on a local Prefect server instance, the storage and infrastructure blocks you created would not also be configured on Prefect Cloud. You must configure new storage and infrastructure blocks for any Prefect Cloud workspace.
Using storage blocks with deployments¶
To demonstrate using a storage block, we'll create a new variation of the deployment for the log_flow example from the deployments tutorial. For this deployment, we'll specify using the storage block created earlier by passing -sb s3/log-test or --storage-block s3/log-test to the prefect deployment build command.
$ prefect deployment build ./log_flow.py:log_flow -n log-flow-s3 -sb s3/log-test -q test -o log-flow-s3-deployment.yaml
Found flow 'log-flow'
Successfully uploaded 3 files to s3://bucket-full-of-sunshine/flows/log-test
Deployment YAML created at
'/Users/terry/test/dplytest/prefect-tutorial/log-flow-s3-deployment.yaml'.
Note that with the -sb s3/log-test option the build process uploads the flow script files to s3://bucket-full-of-sunshine/flows/log-test.
What did we do here? Let's break down the command:
prefect deployment buildis the Prefect CLI command that enables you to prepare the settings for a deployment../log_flow.py:log_flowspecifies the location of the flow script file and the name of the entrypoint flow function, separated by a colon.-n log-flow-s3specifies a name for the deployment. For ease of identification, the name includes a reference to the S3 storage.-sb s3/log-testspecifies a storage block by type and name.-q testspecifies a work queue for the deployment. Work pools direct scheduled runs to agents. Since we didn't specify a work pool with-p, the default work pool will be used.-o log-flow-s3-deployment.yamlspecifies the name for the deployment YAML file. We do this to create a new deployment file rather than overwriting the previous one.
In deployments, storage blocks are always referenced by name in the format type/name, with type and name separated by a forward slash.
typeis the type of storage block, such ass3,azure, orgcs.nameis the name you specified when creating the block.
If you used a different storage block type or block name, your command may be different.
Now you can apply the deployment YAML file to create the deployment on the API.
$ prefect deployment apply log-flow-s3-deployment.yaml
Successfully loaded 'log-flow-s3'
Deployment 'log-flow/log-flow-s3' successfully created with id
'73b0288e-d5bb-4b37-847c-fa68fda39c81'.
To execute flow runs from this deployment, start an agent that pulls work from the 'test'
work pool:
$ prefect agent start -q 'test'
When you create flow runs from this deployment, the agent pulls the flow script from remote storage rather than local storage. This enables more complex flow run scenarios such as running flows on remote machines, in Docker containers, and more. We'll take a closer look at these scenarios in a future tutorial.
Infrastructure¶
Similar to storage blocks, infrastructure blocks contain configuration for interacting with external systems. Specifically, infrastructure includes settings that agents use to create an execution environment for a flow run.
Infrastructure includes configuration for environments such as:
- Docker containers
- Kubernetes Jobs
- Process configuration
Most users will find it easiest to configure new infrastructure blocks through the Prefect server or Prefect Cloud UI.
You can see any previously configured storage blocks by opening the Prefect UI and navigating to the Blocks page. To create a new infrastructure block, select the + button on this page. Prefect displays a page of available block types. Select run-infrastructure from the Capability list to filter to just the infrastructure blocks.
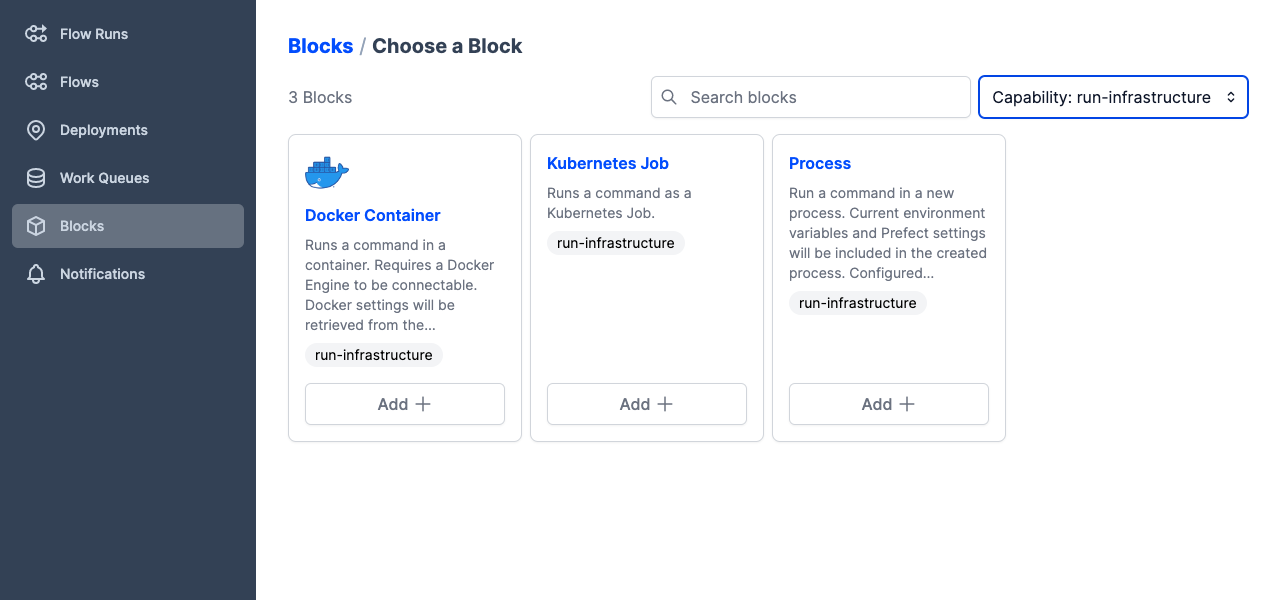
Use these base blocks to create your own infrastructure blocks containing the settings needed to run flows in your environment.
For example, find the Docker Container block, then select Add + to see the options for a Docker infrastructure block.
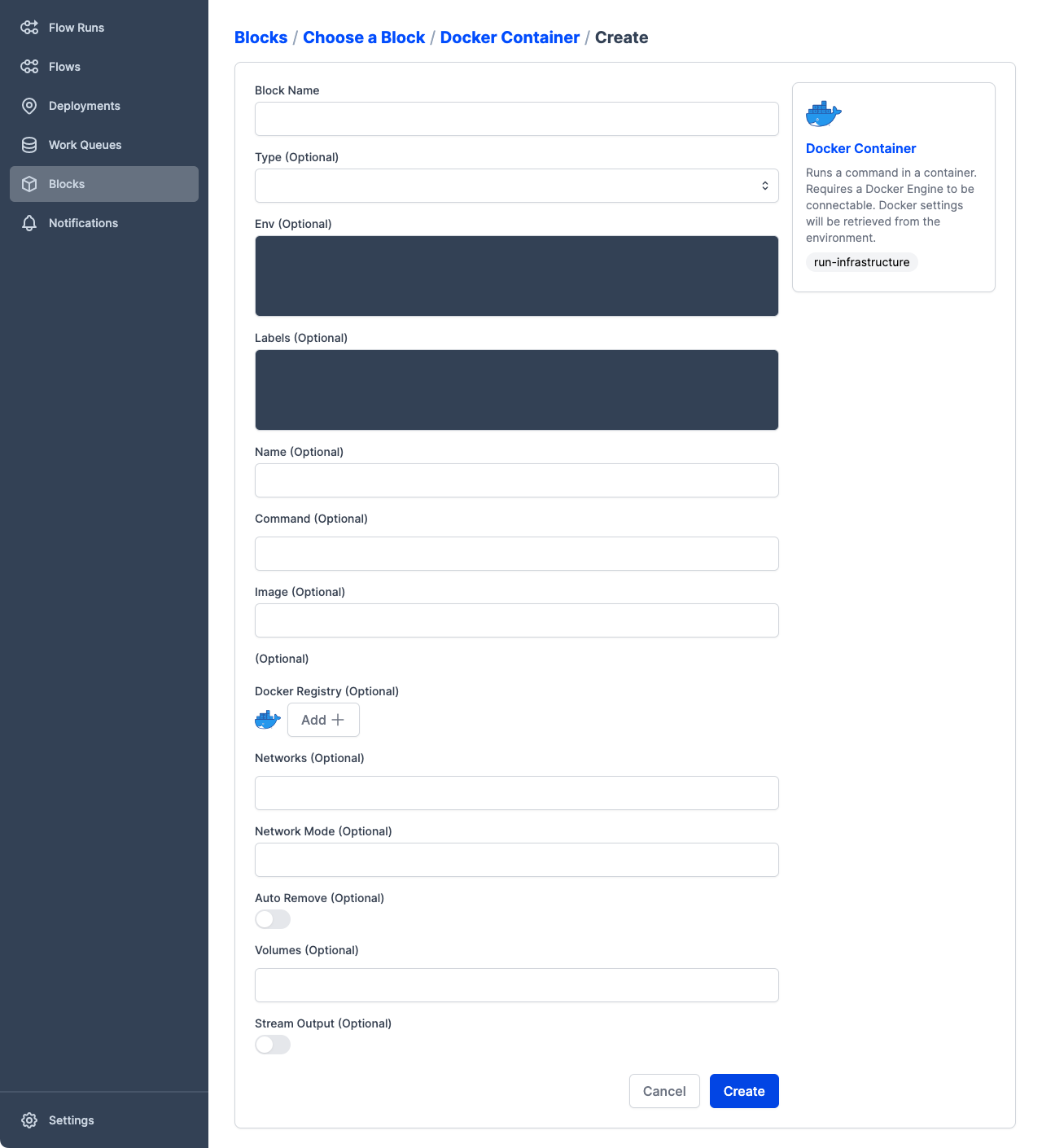
We're not going to create a custom infrastructure block until a later tutorial, so select Cancel to close the form.
Using infrastructure blocks with deployments¶
To use an infrastructure block when building a deployment, the process is similar to using a storage block. You can specify a custom infastructure block to the prefect deployment build command with the -ib or --infra-block options, passing the type and name of the block in the format type/name, with type and name separated by a forward slash.
typeis the type of storage block, such asdocker-container,kubernetes-job, orprocess.nameis the name you specified when creating the block.
The prefect deployment build command also supports specifying a built-in infrastructure type prepopulated with defaults by using the --infra or -i options and passing the name of the infrastructure type: docker-container, kubernetes-job, or process.
Sharing blocks between different deployments¶
One of the major benefits of Prefect blocks is the ability to share common configuration across a diverse set of uses. This includes sharing storage and infrastructure configuration between your deployments.
Sharing storage¶
Every storage block exposes a base path (for example, an S3 bucket name or a GitHub repository). If you are sharing this block across multiple deployments, you most likely want each deployment to be stored in a subpath of the storage block's basepath to ensure independence. To enable this, deployments expose a path field that allows you to specify subpaths of storage for that deployment. Let's illustrate by extending our example above to store our deployment artifacts in a subdirectory of our S3 bucket called log-flow-directory:
$ prefect deployment build ./log_flow.py:log_flow \
-n log-flow-s3 \
-sb s3/log-test \
-q test \
-o log-flow-s3-deployment.yaml \
--path log-flow-directory
Found flow 'log-flow'
Successfully uploaded 3 files to s3://bucket-full-of-sunshine/flows/log-test/log-flow-directory
Deployment YAML created at
'/Users/terry/test/dplytest/prefect-tutorial/log-flow-s3-deployment.yaml'.
Note that we used the --path option on the build CLI to provide this information. Other ways of specifying a deployment's path include:
- Providing a value for
pathtoDeployment.build_from_flowor atDeploymentinitialization (see the API reference for more details). - Prefect offers syntatic sugar on storage block specification where the path can be provided after the block slug:
-sb s3/log-test/log-flow-directory.
Sharing infrastructure¶
Sharing infrastructure blocks between deployments is just as straightforward: every deployment exposes an infra_overrides field that can be used to target specific overrides on the base infrastructure block. These values can be set via CLI (--override) or Python (by providing a properly structured infra_overrides dictionary).
When specified via CLI, overrides must be dot-delimited keys that target a specific (and possibly nested) attribute of the underlying infrastructure block. When specified via Python, overrides must be provided as a possibly nested dictionary. This is best illustrated with examples:
- Providing a custom environment variable: every infrastructure block exposes an
envfield that contains a dictionary of environment variables and corresponding values. To provide a specific environment variable on a deployment, passenv.ENVIRONMENT_VARIABLE=VALUEto either the CLI or theinfra_overridesdictionary as a key/value pair. - Docker image override: every Docker-based infrastructure block exposes an
imagefield referencing the Docker image to use as a runtime environment. Overriding this is as simple as--override image=my-custom-registry/my-custom-image:my-custom-tag.
Specifying blocks in Python¶
As before, we can configure all of this via Python instead of the CLI by modifying our deployment.py file created in the previous tutorial:
# deployment.py
from log_flow import log_flow
from prefect.deployments import Deployment
from prefect.blocks.core import Block
storage = Block.load("s3/log-test")
deployment = Deployment.build_from_flow(
flow=log_flow,
name="log-simple",
parameters={"name": "Marvin"},
infra_overrides={"env": {"PREFECT_LOGGING_LEVEL": "DEBUG"}},
work_queue_name="test",
storage=storage,
)
if __name__ == "__main__":
deployment.apply()
This recipe for loading blocks is useful across a wide variety of situations, not just deployments. We can load arbitrary block types from the core Block class by referencing their slug.
Next steps: Flow runs with Docker
Continue on to the Docker tutorial where we'll put storage, infrastructure, and deployments together to run a flow in a Docker container.